大模型训练工具之Deepspeed
什么是deepspeed?
大模型火了之后,大模型的分布式训练自然而然成为了一个研究热点,其中 deepspeed 无疑是 最火爆的开源分布式训练框架之一。
在开始讲deepspeed前,先整理一下大模型分布式训练的关键逻辑和问题,这样更容易理解一些技术点到底是为什么。
单卡时代
之前,一个深度学习模型并没有超过单个显卡的显存,其全部模型参数都可以加载到一个GPU中, 并且在单卡完成整个训练或者推理过程。这个时代,大家都能很愉快的玩耍。
多卡并行时代
后来随着显卡越来越便宜,训练数据量越来越多,人们逐渐开始研究如何利用多卡加速模型的训练,实现思路也很常规, 就是多张卡同时参与训练,每张卡都独立加载整个模型,并且独立进行前后向过程。通过把训练数据的一个大的 batch 分成多个小 batch,每张卡独立处理一个小 batch,最后再把各个卡上的梯度汇总整合起来,在一个主卡(主进程) 中计算新的参数值,然后再把新参数同步到各个卡中,这样实现数据的并行训练,所以称之为数据并行(Data Parallel,DP ) 。
大模型时代
进入大模型时代后,一张卡的显存不足以加载完整的模型或者完成一个训练过程。那如何解决这个问题呢?
-
首先要弄清楚的是,消耗显存的都有哪些?
- 模型的参数。
- 前向过程中,一些中间计算结果以及激活值(即激活函数的执行结果)。
- 反向过程中,每个参数的梯度值。
- 优化器的状态。比如
adam算法,需要为每个参数再保存一个一阶动量和二阶动量。
-
接下来,思考如何解决内存不足的问题。核心思路其实很简单,主要有两个方向:
-
先不把全部数据加载到
GPU显存,暂时存放在别的地方,需要的时候再同步到GPU显存中,用完就扔掉。-
把参数放到
CPU内存中或者高速SSD中(支持NVMe的ssd,走的PCI-E总线),这就是deepspeed中的offload技术。 -
多张GPU卡,每张卡保存一部分,需要的时候再从其他卡同步过来,这就是参数分割。
-
-
降低内存的需求。原来每个参数都是
float32类型,占用4个字节。-
改成半精度,用2个字节的
float16替代4个字节float32,显存需求一下就降低一半。 -
用量化技术,用2个字节的
int16或者1个字节的int8代替4字节的float32。
-
-
显然,每种方法都不是完美的,都有一定的局限性并且会引入新的问题,比如:
-
参数进行多卡分割或者
offload,比如会增加大量数据同步通信时间,不要小看这部分时间消耗,相对于GPU的显存访问速度而言, 多机器之间的网络通信、单机多卡之间通信、cpu内存到GPU内存的通信,这些都是巨大的延迟。 -
模型运行中,大量的浮点数乘法,产生很多很小的浮点数,降低参数精度,会造成数据溢出,导致出问题,即使不溢出,也损失了数据准确性。 模型训练时,梯度误差大,导致损失不收敛。模型推理时,误差变大,推理效果变差。
参数分割策略
说到分割参数,无论是多GPU之间分割参数,还是 offload 到CPU内存,都需要对参数进行分割分组。 这就涉及到多种划分策略。
-
按照模型的层(Layer)进行分割,保留每一层(Layer)为整体,不同层存储在不同的
GPU中, 多个层(GPU)串行在一起,需要串行执行,这就是所谓的 流水线并行(Pipeline Parallel,PP)。时间效率很差, 并且如果某一层的参数量就很大并超过了单卡的显存就尴尬。当然可以通过异步执行一定程度解决时间效率差的问题,有兴趣的读者可以研读相关资料。 -
把参数张量切开,切开张量分开存储很容易,但切开之后,张量计算的时候怎么办?这里可以分两种策略。
- 张量的计算过程也是可以切割,这样把一个大的张量,切分成多个小张量,每张
GPU卡只保存一个小片段,每个小张量片段(GPU卡)独立进行相关计算,最后在需要的时候合并结果就行了。这种思路就称为 张量并行(Tensor Parallel,TP) ,Megatron就是走的这个路线。 - 同样是把参数张量分割,每张卡只保存一个片段。但是需要计算的时候,每张卡都从其他卡同步其它片段过来,恢复完整的参数张量,再继续数据计算。
Deepspeed选取的这个策略,这个策略实现起来更简单一些。
- 张量的计算过程也是可以切割,这样把一个大的张量,切分成多个小张量,每张
降低精度
降低参数精度也有讲究,有些地方可以降低,有些地方就不能降低,所以一般是混合精度。 半精度还有另一个好处,就是 计算效率更高,两个字节的计算速度自然是高于4个字节的。 在模型训练过程中,参数的梯度是非常重要的,参数更新累积梯度变化时,如果精度损失太多会导致模型不收敛。 所以优化器的状态一般需要保留 float32 类型,具体参看下图。 有关混合精度更细节内容请参考论文 Mixed Precision Training
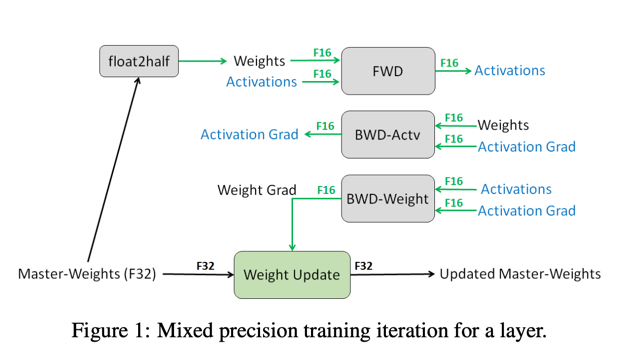
实际上,GPU 显存不足的问题更多的是靠上面的参数分割来解决,半精度的应用更多的是为了提高计算速度。
流水线并行、张量并行,把模型一次完整的计算过程(前反向)分拆到多个 GPU 上进行, 所以这两者都被称为模型并行(Model Parallel,MP)。 而如果每张卡都能进行模型一次完整前后向计算,只是每张卡处理不同的训练数据批次(batch), 就称为数据并行(Data Parallel,DP)。 deepspeed 对参数进行了分割,每张卡存储一个片段,但在进行运算时, 每张卡都会恢复完整的参数张量,每张卡处理不同的数据批次, 因此 deepspeed 属于数据并行。
最后总结一下, 针对大模型的训练有三种并行策略,理解起来并不复杂:
数据并行:模型的计算过程没有分割,训练数据是分割并行处理的。
模型并行:模型的计算过程被分割。
- 流水线并行:模型按照层(Layer)切分。
- 张量并行:把参数张量切分,并且将矩阵乘法分解后多 GPU 并行计算。
DeepSpeed横空出世
基于上诉实际需求,DeepSpeed应运而生。DeepSpeed是由Microsoft提供的分布式训练工具,旨在支持更大规模的模型和提供更多的优化策略和工具。与其他框架相比,DeepSpeed支持更大规模的模型和提供更多的优化策略和工具。其中,主要优势在于支持更大规模的模型、提供了更多的优化策略和工具(例如 ZeRO 和 Offload 等)。
zero简介
ZeRO论文:《ZeRO:Memory Optimizations Toward Training Trillion Parameter Models》
ZeRO-Offload论文:《ZeRO-Offload:Democratizing Billion-Scale Model Training.》
NVMe技术论文:《 ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning》
ZeRO(Zero Redundancy Optimizer)是一种用于优化大规模深度学习模型训练的技术。它的主要目标是降低训练期间的内存占用、通信开销和计算负载,从而使用户能够训练更大的模型并更高效地利用硬件资源。
ZERO论文首先分析了模型训练中内存主要消耗在两个方面:
model states:模型状态,包括包括优化器参数(例如Adam的动量和方差)、梯度、模型参数residual states:剩余状态,包括包括激活函数、临时缓冲区、内存碎片
ZERO分别使用ZeRO-DP和ZeRO-R来优化model states和residual states。如上图所示,ZeRO-DP包括三个阶段:
ZeRO 第 1 阶段:优化器状态分割 $P_{os}$: 在每个gpu中保存全部的参数和梯度,但是只保存 $1/{N_d}$ 的优化器状态变量。通过将优化器状态进行分割,实现4倍的内存减少,同时保持与DP相同的通信量。
ZeRO 第 2 阶段:梯度分割 $P_{os+g}$:每个gpu中只保存 $1/{N_d}$ 的梯度,实现8倍的内存减少,并保持与DP相同的通信量。
ZeRO 第 3 阶段:参数分割 $P_{os+g+p}$: 每个gpu中只保存 $1/{N_d}$ 的参数 ,实现64倍的内存减少,通信量会略微增加50%。作者通过用少量的计算的成本和通信成本换来了大幅的内存节省。
ZeRO-Infinity是ZeRO的一个扩展版本,它允许将模型参数存储在CPU内存或NVMe存储上,而不是全部存储在GPU内存中,最终在有限资源下能够训练前所未有规模的模型(在单个NVIDIA DGX-2节点上微调具有1万亿参数的模型),而无需对模型代码进行重构。与此同时,它实现了出色的训练吞吐量和可扩展性,不受有限的CPU或NVMe带宽的限制。
deepspeed简介
2020年3月Microsoft Research首次开源了DeepSpeed ,是一个用于训练大规模深度学习模型的优化工具,它实现了 ZeRO 论文中描述的所有内容,可以提高训练速度和内存效率,并降低资源需求。目前它提供以下支持:
- Optimizer state partitioning (ZeRO stage 1):优化器状态分区
- Gradient partitioning (ZeRO stage 2):梯度划分。DeepSpeed ZeRO-2 主要仅用于训练,因为其功能对推理没有用处。
- Parameter partitioning (ZeRO stage 3):参数划分。DeepSpeed ZeRO-3 也可用于推理,因为它允许在多个 GPU 上加载大型模型,而这在单个 GPU 上是不可能的。
- Custom mixed precision training handling:混合精度训练。
- A range of fast CUDA-extension-based optimizers:一系列基于 CUDA 扩展的快速优化器
- ZeRO-Offload to CPU and NVMe:数据卸载到 CPU 和 NVMe。
接下来我们学习如何使用这个强大的工具。
如何使用deepspeed?
安装
通过pypi安装库:
1
pip install deepspeed
或通过transformers的extras安装:
1
pip install transformers[deepspeed]
本地构建:
1
2
3
4
5
6
git clone https://github.com/microsoft/DeepSpeed/
cd DeepSpeed
rm -rf build
TORCH_CUDA_ARCH_LIST="8.6" DS_BUILD_CPU_ADAM=1 DS_BUILD_UTILS=1 pip install . \
--global-option="build_ext" --global-option="-j8" --no-cache -v \
--disable-pip-version-check 2>&1 | tee build.log
多GPU部署
DeepSpeed有两种启动方式:
- 使用PyTorch启动器:保持PyTorch的训练流程,只在其中使用DeepSpeed的一些配置文件和设置来改进训练速度和内存效率。好处是更容易集成到现有的PyTorch代码中,因为它不需要你改变整个训练流程。
1
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json
- 使用DeepSpeed提供的启动器:DeepSpeed提供了自己的启动器,它是一个独立的命令行工具,用于配置和启动DeepSpeed训练。这种方式适用于需要更高度自定义控制的情况,可以轻松在不同环境中部署。
1
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
上述命令中,各个字段的含义如下:
deepspeed: DeepSpeed启动器(launcher)--num_gpus=2(可选): 指定要使用的GPU数量,如果要启用所有的GPU,可以省略此参数。your_program.py: 用户的训练脚本。在训练脚本中使用DeepSpeed提供的优化器、分布式训练支持和其他功能来优化您的训练任务。(DeepSpeed通常被集成到用户的自定义脚本中,以提供更高效的训练和更好的硬件资源利用率,所以DeepSpeed库本身没有训练代码。)<normal cl args>: 一些普通的命令行参数,以指定训练任务的不同配置。--deepspeed ds_config.json: 使用DeepSpeed的配置文件ds_config.json来配置训练过程。
下面是在DeepSpeed上使用所有可用GPU运行run_translation.py的示例:
1
2
3
4
5
6
7
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
单GPU部署
如果是使用一个 GPU 部署 DeepSpeed,只需要设置 --num_gpus=1,明确告诉 DeepSpeed 仅使用一个 GPU。
1
2
3
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
...
为什么要使用只有一个GPU的DeepSpeed?
- 它具有ZeRO-offload功能,可以将一些计算和内存委派给主机的CPU和RAM,从而为模型的需求留下更多的GPU资源-例如更大的批次大小,或启用通常无法容纳的非常大的模型。
- 它提供了智能的GPU内存管理系统,最小化内存碎片化,这样再次可以适应更大的模型和数据批次。
要在具有一个GPU的DeepSpeed上获得巨大改进的关键是在配置文件中至少有以下配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true
}
}
多节点部署
假设你有2个拥有8个GPU的节点。你可以通过ssh hostname1访问第一个节点,通过ssh hostname2访问第二个节点,并且两者必须能够通过本地ssh在没有密码的情况下相互访问。当然,你需要将这些主机(节点)名称重新命名为你使用的实际主机名称。
torch.distributed.run启动器
例如,要使用torch.distributed.run,你可以执行以下操作:
1
2
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
你必须ssh到每个节点并在每个节点上运行相同的命令!不用着急,启动器会等待直到两个节点同步。
deepspeed启动器
首先必须创建一个hostfile文件:
1
2
hostname1 slots=8
hostname2 slots=8
然后你可以启动它:
1
2
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
与torch.distributed.run启动器不同,deepspeed将自动在两个节点上启动此命令!
ZeRO-0配置
阶段0是禁用所有分片类型,仅使用DeepSpeed作为DDP。你可以使用以下方法启用它:
1
2
3
4
5
{
"zero_optimization": {
"stage": 0
}
}
这将完全禁用ZeRO,而你无需更改其他任何内容。
ZeRO-1配置
第1阶段是第2阶段减去梯度分片。你可以尝试使用以下方法来稍微加快速度,只在优化器状态中进行分片:
1
2
3
4
5
{
"zero_optimization": {
"stage": 1
}
}
ZeRO-2示例
这是一个完整的ZeRO-2自动配置文件ds_config_zero2.json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
这是一个完整的手动设置的ZeRO-2配置文件,主要是为了让你看到典型值的外观,但我们强烈建议使用其中具有多个auto设置的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
ZeRO-3示例
这是一个完整的ZeRO-3自动配置文件ds_config_zero3.json:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
这是一个完整的手动设置的ZeRO-3配置文件,主要是为了让你看到典型值的外观,但我们强烈建议使用其中具有多个auto设置的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": 1e6,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
ZeRO-2与ZeRO-3性能进行比较
如果在其他所有配置保持不变的情况下,ZeRO-3可能比ZeRO-2慢,因为前者需要收集模型权重,并且比ZeRO-2执行的操作更多。如果ZeRO-2满足你的需求,并且你不需要在几个GPU之间扩展,那么可以选择使用ZeRO-2。重要的是要了解,ZeRO-3可以以更高的可扩展性为代价提供更高的性能。
可以调整ZeRO-3配置,使其性能更接近于ZeRO-2:
- 将
stage3_param_persistence_threshold设置为一个非常大的值-大于最大的参数值,例如6 * hidden_size * hidden_size。这将使参数保留在GPU上。 - 关闭
offload_params,因为ZeRO-2没有该选项。
即使你不更改stage3_param_persistence_threshold,只要将offload_params关闭,性能可能会显着提高。当然,这些更改将影响你可以训练的模型的大小。因此,这些更改可让你在可扩展性和速度之间进行权衡,具体取决于你的需求。
NVMe支持
通过使用NVMe内存可以扩展GPU和CPU内存,ZeRO-Infinity允许训练规模非常大的模型。由于智能划分和平铺算法,每个GPU在卸载过程中需要发送和接收非常少量的数据,因此现代NVMe被证明适合为训练过程提供总共更大的内存池。ZeRO-Infinity需要启用ZeRO-3。
以下配置示例启用了将优化器状态和参数同时卸载到NVMe:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
}
你可以选择同时卸载优化器状态和参数到NVMe,或者只卸载它们中的一个,或者都不卸载。例如,如果你有大量的CPU内存可用,可以只卸载到CPU内存,因为它的速度更快(提示:”device”: “cpu”)。
确保nvme_path实际上是一个NVMe,因为它可以与常规硬盘或固态硬盘一起使用,但速度要慢得多。快速可扩展的训练是针对现代NVMe传输速度设计的(按照当前编写时,最大读取速度约为3.5GB / s,写入速度约为3GB / s)。
如何选择最佳性能的ZeRO阶段和卸载方式
通常,以下情况适用:
-
从速度角度来看(左边比右边快)
阶段0(DDP)> 阶段1 > 阶段2 > 阶段2 + 卸载 > 阶段3 > 阶段3 + 卸载
-
从GPU内存使用率来看(右边比左边更高效)
阶段0(DDP)< 阶段1 < 阶段2 < 阶段2 + 卸载 < 阶段3 < 阶段3 + 卸载
因此,当你希望获得最快的执行速度,同时适应最小数量的GPU时,可以按照以下流程进行操作。我们从最快的方法开始,如果发生GPU OOM,然后转到更低速的方法,但使用更少的GPU内存。依此类推。
首先将批次大小设置为1(你始终可以使用渐进累积进行任何所需的有效批次大小)。
-
启用
--gradient_checkpointing 1(HF Trainer)或直接model.gradient_checkpointing_enable()- 如果发生OOM,则 -
尝试首先使用ZeRO阶段2。如果发生OOM,则
-
尝试使用ZeRO阶段2 +
offload_optimizer。如果发生OOM,则 -
切换到ZeRO阶段3。如果发生OOM,则
-
将
offload_param设置为cpu。如果发生OOM,则 -
将
offload_optimizer设置为cpu。如果发生OOM,则 -
如果仍然无法适应批次大小为1,请检查各种默认值,并在可能的情况下将其降低。例如,如果使用
generate并且不使用宽的搜索束,将其变为更窄,因为它会消耗大量内存。 -
使用半精度而不是fp32 - 在Ampere及更高的GPU上使用
bf16,在较旧的GPU架构上使用fp16。 -
如果仍然发生OOM,可以添加更多硬件或启用ZeRO-Infinity-将
offload_param和offload_optimizer切换到nvme。你需要确保它是一个非常快速的nvme。
当你的批次大小为1时,没有发生OOM,请测量有效吞吐量。
接下来,尝试增加批次大小,尽可能大,因为批次大小越大,GPU执行的效率越高,因为它们在乘以矩阵时表现最佳,而这些矩阵都非常大。
你可以关闭一些卸载功能或者降低 ZeRO 阶段,并增加/减少批大小,然后再测量有效吞吐量。反复测试直到满意。
这些注意事项主要是为训练模式编写的,但大部分适用于推理模式。例如,在推理期间,渐变检查点是无效操作,因为它只在训练期间有用。
如果你从头开始训练某个东西,请尝试使张量的形状可被 16 整除(例如隐藏大小)。对于批大小,请至少尝试使其可被 2 整除。
activation checkpointing或gradient checkpointing
activation checkpointing和gradient checkpointing是两个相互独立的术语,指的是同一方法。这非常令人困惑,但情况就是这样。
gradient checkpointing允许你在 GPU 内存和速度之间进行权衡,它可以克服 GPU OOM 或增加批大小,从而通常可以获得更好的性能。
因此,你有两种方法可以利用此非常有益的功能:
- 如果要使用 HF transformers模型,可以使用
model.gradient_checkpointing_enable()或在 HF Trainer 中使用--gradient_checkpointing,它将自动为你启用此功能。在那里使用了torch.utils.checkpoint。 - 如果你自己编写了模型,并且想使用 DeepSpeed 的activation checkpointng,则可以使用此处规定的 API。你还可以使用 HF transformers 建模代码并将
torch.utils.checkpoint替换为 DeepSpeed 的 API。后者更加灵活,因为它允许你将前向激活卸载到 CPU 内存,而不是重新计算它们。
优化器和调度器
只要不启用 offload_optimizer,就可以混合使用 DeepSpeed 和 HuggingFace 的调度器和优化器,除了使用 HuggingFace 调度器和 DeepSpeed 优化器的组合之外:
| 组合 | HF 调度器 | DS 调度器 |
|---|---|---|
| HF 优化器 | 是 | 是 |
| DS 优化器 | 否 | 是 |
可以使用非 DeepSpeed 优化器,只要它具有 CPU 和 GPU 实现(不包括 LAMB)。
优化器
优化器必须通过此处进行配置。DeepSpeed 的主要优化器是 Adam、AdamW、OneBitAdam 和 Lamb。这些优化器已经经过全面测试,因此建议使用。它还可以从 torch 导入其他优化器。如果不在配置文件中配置 optimizer 条目,则 [Trainer] 将自动将其设置为 AdamW,并使用提供的值或默认值设置以下命令行参数: --learning_rate、--adam_beta1、--adam_beta2、--adam_epsilon 和 --weight_decay。
以下是自动配置的 AdamW 的示例:
1
2
3
4
5
6
7
8
9
10
11
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
请注意,命令行参数将设置配置文件中的值。这样就有了一个定义值的唯一来源,并且避免了例如在不同位置设置学习率为不同值时难以找到的错误。命令行的规则优先。被覆盖的值有:
lr使用--learning_rate的值betas使用--adam_beta1和--adam_beta2的值eps使用--adam_epsilon的值weight_decay使用--weight_decay的值
因此,请记住在命令行上调整共享超参数。
你还可以显式地设置值:
1
2
3
4
5
6
7
8
9
10
11
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.001,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
}
}
但是,你需要自己同步 [Trainer] 命令行参数和 DeepSpeed 配置文件。
如果要使用其他未列出的优化器,必须将其添加到顶级配置中。
1
2
3
{
"zero_allow_untested_optimizer": true
}
与 AdamW 类似,你可以配置其他官方支持的优化器。只需记住这些优化器可能具有不同的配置值。例如,对于 Adam,你将希望 weight_decay 在0.01 左右。
此外,当与卸载一起使用时,使用 Deepspeed 的 CPU Adam 优化器时效果最好。如果要在卸载时使用其他优化器,自 deepspeed==0.8.3 以来,你还需要添加:
1
2
3
{
"zero_force_ds_cpu_optimizer": false
}
到顶级配置。
调度器
DeepSpeed 支持 LRRangeTest、OneCycle、WarmupLR 和 WarmupDecayLR 学习率调度器。完整文档在这里。
以下是 DeepSpeed 和 🤗Transformers 之间调度器的重叠部分:
WarmupLR通过--lr_scheduler_type constant_with_warmup。WarmupDecayLR通过--lr_scheduler_type linear。这也是--lr_scheduler_type的默认值,因此,如果不配置调度器,这是默认的配置。
如果不在配置文件中配置 scheduler 条目,则 [Trainer] 将使用 --lr_scheduler_type、--learning_rate 和 --warmup_steps 或 --warmup_ratio 的值配置 🤗Transformers 版本。
以下是自动配置的 WarmupLR 的示例:
1
2
3
4
5
6
7
8
9
10
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
由于使用了 “auto”,[Trainer] 参数将在配置文件中设置正确的值。这样就有了一个定义值的唯一来源,并且避免了例如在不同位置设置学习率为不同值时难以找到的错误。命令行优先。设置的值为:
warmup_min_lr的值为0。warmup_max_lr的值为--learning_rate。warmup_num_steps的值为如果提供了--warmup_steps,则使用该值。否则,将使用--warmup_ratio乘以训练步骤的数量,并向上取整。total_num_steps的值为--max_steps的值,否则在运行时根据环境、数据集的大小和其他命令行参数自动推导出来(WarmupDecayLR需要)。
当然,你可以接管配置值中的任何一个或多个,并自行设置:
1
2
3
4
5
6
7
8
9
10
{
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.001,
"warmup_num_steps": 1000
}
}
}
但是,你需要自己同步 [Trainer] 命令行参数和 DeepSpeed 配置。
例如,对于 WarmupDecayLR,可以使用以下条目:
1
2
3
4
5
6
7
8
9
10
11
12
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"last_batch_iteration": -1,
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
它将在加载时设置 total_num_steps、warmup_max_lr、warmup_num_steps 和 total_num_steps。
fp32 精度
Deepspeed 支持完全的 fp32 和 fp16 混合精度。
由于 fp16 混合精度需要的内存更少,速度更快,所以你唯一不希望使用的情况是当你使用的模型在此训练模式下表现不佳时。这样的模型可能会溢出或下溢,导致损失为 NaN。如果是这种情况,你将希望使用完全的 fp32 模式,并通过显式禁用默认的 fp16 混合精度模式来禁用它:
1
2
3
4
5
{
"fp16": {
"enabled": false,
}
}
如果使用 Ampere 架构的 GPU,从 pytorch 1.7 版本开始,默认情况下会自动切换为使用更高效的 tf32 格式进行某些操作,但结果仍然是 fp32。
使用 🤗Trainer,你可以使用 --tf32 启用它,或使用 --tf32 0 或 --no_tf32 禁用它。默认情况下,PyTorch 使用默认值。
1
2
3
4
5
{
"bf16": {
"enabled": "auto"
}
}
bf16 的动态范围与 fp32 相同,因此不需要有损失区。
当使用 --bf16 或 --bf16_full_eval 命令行参数时,启用此模式。
你还可以显式启用/禁用此模式:
1
2
3
4
5
{
"bf16": {
"enabled": true
}
}
提示:
如果你在训练时使用 梯度累积,并启用了 bf16,你需要注意,它将以 bf16 累积梯度,这可能不是你想要的,因为此格式的精度较低,可能会导致有损累积。
NCCL 集合
有一个 dtype 是训练制度,还有一个单独的 dtype 用于通信集合,如各种reduce和gathering/scattering操作。
所有gather/scatter操作都使用与数据相同的 dtype,因此,如果你正在使用 bf16 训练制度,则以 bf16 进行gather。gather是一个非损失操作。
各种reduce操作可能会非常有损,例如当梯度在多个 GPU 上进行平均时,如果通信是在 fp16 或 bf16 上执行的,则结果很可能会有损-因为在低精度下添加多个数字时,结果不是精确的。特别是在使用 bf16 时更加如此,因为它的精度低于 fp16。通常情况下,fp16 已经足够好,因为平均梯度通常非常小。因此,默认情况下,在半精度训练中使用 fp16 作为reduce操作的默认值。但是,你对此功能有完全的控制,并且如果选择,可以添加一些额外的开销,并确保在累计完成后将其累积到半精度 dtype 中,直到结果准备好后才降级到你正在训练的半精度“dtype”。
为了覆盖默认值,你只需添加一个新的配置条目:
1
2
3
{
"communication_data_type": "fp32"
}
自动混合精度
你可以使用 pytorch-like AMP 方法或 apex-like 方法来使用自动混合精度:
fp16
要配置带有 fp16(float16)的 pytorch-like AMP 模式,请设置:
1
2
3
4
5
6
7
8
9
10
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
[Trainer] 将根据 args.fp16_backend 的值和 args.fp16_opt_level 的值自动启用或禁用此模式。
当传递 --fp16 --fp16_backend amp --fp16_opt_level 01 命令行参数时,将启用此模式。
你还可以显式配置此模式:
1
2
3
4
5
6
7
8
9
10
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
但是,你需要自己同步 [Trainer] 的命令行参数和 DeepSpeed 的配置文件。
bf16
如果希望使用 bf16(bfloat16)而不是 fp16,则可以使用以下配置部分:
1
2
3
4
5
{
"bf16": {
"enabled": "auto"
}
}
bf16 与 fp32 具有相同的动态范围,因此不需要有损补。
当传递 --bf16 或 --bf16_full_eval 命令行参数时,启用此模式。
你还可以显式启用/禁用此模式:
1
2
3
4
5
{
"bf16": {
"enabled": true
}
}
故障排除
在启动时,deepspeed进程无回溯地被杀死
如果deepspeed进程在启动时被无回溯地杀死,这通常意味着程序尝试分配的CPU内存超过了系统或进程允许分配的CPU内存,因此操作系统内核杀死了该进程。这是因为你的配置文件很可能同时配置了offload_optimizer和offload_param将其转移到了cpu。如果你有NVMe,如果在ZeRO-3下运行,可以尝试将其分流到NVMe。可以使用以下方法来估计为特定模型需要多少内存。
训练和/或评估/预测损失为NaN
在将以bf16混合精度模式预训练的模型用于不带混合精度的fp16下时,经常会发生损失为NaN的情况。大多数基于TPU并且通常是谷歌发布的模型都属于此类别(例如,几乎所有基于t5的模型)。在这种情况下,解决方案是要么使用fp32,要么使用如果你的硬件支持(TPU、Ampere GPU或更新版本)时使用bf16。
另一个问题可能与使用fp16有关。当配置以下部分时:
1
2
3
4
5
6
7
8
9
10
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
并且你在日志中看到Deepspeed报告如下OVERFLOW!的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
这意味着Deepspeed损失缩放器无法找到一个可以克服损失溢出的缩放系数。
在这种情况下,你通常需要提高initial_scale_power的值。将其设置为"initial_scale_power": 32通常可以解决该问题。
注意事项 虽然DeepSpeed有一个可pip安装的PyPI软件包,但强烈建议从源代码进行安装,以便最好地匹配你的硬件,并且如果你需要启用某些功能(如1-bit Adam),在pypi分发中无法使用。
使用非Trainer的Deepspeed集成
当不使用[Trainer]时,[~integrations.HfDeepSpeedConfig]用于将Deepspeed集成到🤗Transformers核心功能中。唯一的需要是处理Deepspeed ZeRO-3参数聚合并在from_pretrained调用期间自动将模型分割到多个GPU上。其他所有操作都需要你自己完成。
当使用[Trainer]时,所有操作都会自动处理。
当不使用[Trainer]时,为了有效地部署DeepSpeed ZeRO-3,你必须在实例化模型之前实例化[~integrations.HfDeepSpeedConfig]对象,并将该对象保持活动状态。
如果你使用Deepspeed ZeRO-1或ZeRO-2,则根本不需要使用HfDeepSpeedConfig。
例如,对于预训练模型:
1
2
3
4
5
6
7
8
9
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed配置对象或文件的路径
# 必须在实例化模型之前运行以检测zero 3
dschf = HfDeepSpeedConfig(ds_config) # 保持此对象的活动状态
model = AutoModel.from_pretrained("gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
或者对于非预训练模型:
1
2
3
4
5
6
7
8
9
10
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed配置对象或文件的路径
# 必须在实例化模型之前运行以检测zero 3
dschf = HfDeepSpeedConfig(ds_config) # 保持此对象的活动状态
config = AutoConfig.from_pretrained("gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
请注意,如果你不使用[Trainer]集成,则完全由你自己负责。基本上按照Deepspeed网站上的文档操作。此外,必须显式配置配置文件-无法使用”auto”值,必须使用实际值。
自定义Deepspeed ZeRO推理
以下示例演示了如何在不使用[Trainer]时进行Deepspeed ZeRO推理,当无法将模型装入单个GPU中时。该解决方案包括使用额外的GPU和/或将GPU内存卸载到CPU内存中。
需要了解的重要细微之处是,ZeRO的设计方式允许在每个GPU上并行处理不同的输入。
示例具有大量注释,并以自我记录方式进行了说明。
确保:
- 如果你有足够的GPU内存,请禁用CPU offload(因为会减慢处理速度)
- 如果你拥有Ampere或更高版本的GPU,请启用
bf16以加快速度。如果你没有这样的硬件,只要不使用以bf16混合精度预训练的任何模型(例如大多数t5模型),你可以启用fp16。这些模型通常在fp16中溢出,并显示垃圾输出。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
#!/usr/bin/env python
# 此脚本演示了在无法将模型装入单个GPU中时如何在推理模式下使用Deepspeed ZeRO。
#
# 1. 使用1个带CPU卸载的GPU
# 2. 或者使用多个GPU
#
# 首先你需要安装deepspeed:pip install deepspeed
#
# 这里我们使用3B "bigscience/T0_3B"模型,它需要大约15GB的GPU RAM-因此可以使用1个较大的或2个较小的GPU来处理它。或者,一个小型的GPU和大量的CPU内存。
#
# 要使用更大的模型,比如需要大约50GB的"bigscience/T0",除非你拥有一个80GB的GPU,否则需要使用2-4个GPU。然后你可以根据需要调整该脚本以处理更多的GPU。
#
# 提供的deepspeed配置还激活了CPU内存卸载,因此,如果你有大量可用的CPU内存,并且不介意减慢速度,应该可以加载通常不适应单个GPU的模型。如果你有足够的GPU内存,如果你不想进行CPU卸载,那么程序将运行得更快-因此禁用该部分。
#
# 要在1个gpu上部署:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# 要在2个gpu上部署:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # 避免关于tokenizers并行性的警告
# 分布式设置
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# 批处理大小必须可被world_size整除,但可以大于world_size
train_batch_size = 1 * world_size
# ds_config 注释:
#
# - 如果你使用的是Ampere或更高版本的GPU,请启用bf16-这将以混合精度运行并且速度更快。
#
# - 对于旧一些的GPU,你可以启用fp16,但仅使用未经bf16预训练的模型-例如,所有官方的t5模型都是经过bf16预训练的。
#
# - 将offload_param.device设置为"none"或完全删除`offload_param`部分,如果你不- 想进行CPU卸载
#
# - 如果使用`offload_param`,你可以手动微调stage3_param_persistence_threshold以控制应保留在GPU上的参数数量- 值越大,卸载的尺寸越小
#
# 有关Deepspeed配置的详细信息,请参见
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# 为了保持与.json的一致性使用相同的格式,只是它在true/false上使用小写
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# 下一行指示transformers在调用模型的`from_pretrained`方法时,使用deepspeed.zero.Init直接在多个gpu上对模型进行分区。
#
# **必须在加载模型AutoModelForSeq2SeqLM.from_pretrained(model_name)之前运行此行**
#
# 否则,模型将首先以常规方式加载,仅在前向时分区,这样会更低效,并且在CPU内存很少的情况下可能会失败
dschf = HfDeepSpeedConfig(ds_config) # 保持此对象的活动状态
# 现在可以加载模型。
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# 初始化Deepspeed ZeRO并仅存储引擎对象
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # 推理模式
# Deepspeed ZeRO可以在每个GPU上处理不相关的输入。因此,对于2个gpu,你可以同时处理2个输入。
# 如果只有一个要处理的输入,则需要同时将相同的字符串传递给两个gpu
# 如果只有一个GPU,那么你只有rank 0。
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
将其保存为t0.py并运行:
1
2
3
4
5
6
7
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
这是一个非常基本的示例,你需要根据自己的需求进行调整。
generate细微差别
使用ZeRO Stage-3和多个GPU时,必须通过调用generate(..., synced_gpus=True)来同步GPU。如果不这样做,如果某个GPU在其他GPU之前完成生成,则整个系统将发生挂起,因为其他GPU将无法从停止生成的GPU接收权重分片。